

Why Auto-Labelling Still Needs A Human Reality Check
29/04/2026
Ghost Points and Occlusions: Solving the Noise Problem
04/05/2026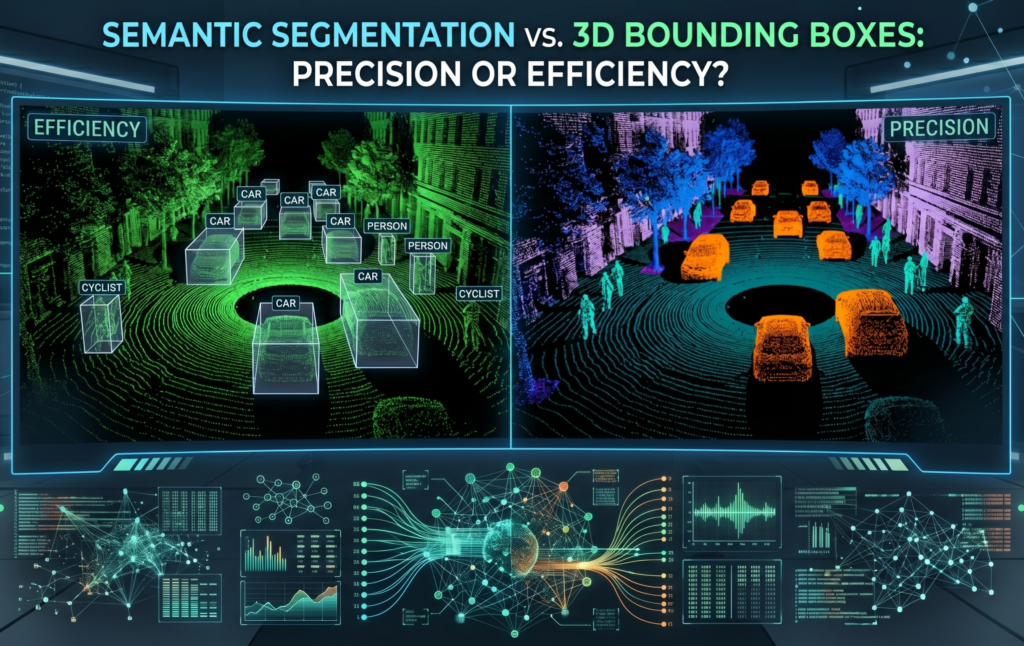
Semantic Segmentation vs. 3D Bounding Boxes: Precision or Efficiency?
9 min read
In this article, you'll learn about the different methods for 3D point cloud annotation. You'll also understand the advantages and tradesoffs of each.
Do you need to know where the object is, or do you need to know every single point that is the object?
The answer to this question determines whether you use 3D Bounding Boxes or Semantic Segmentation. While they might seem like two sides of the same coin, the technical requirements and the human effort involved are worlds apart.
3D Bounding Boxes: The Power of Localization
Commonly referred to as cuboids, 3D bounding boxes are the standard for object detection and tracking. An annotator draws a box that encompasses an object, defining its length, width, height, and orientation.
Key Characteristics:
- Localization: It tells the system exactly where an object is located in a 3D coordinate system (X, Y, Z).
- Efficiency: From a manual standpoint, cuboids are relatively fast to produce. A skilled annotator can box a vehicle in seconds.
- Use Cases: Ideal for autonomous driving tasks where you simply need to maintain a "safety bubble" around other cars or pedestrians.
The tradeoff: Cuboids are "loose." They include "empty space" within the box that doesn't actually belong to the object, such as the air between a truck's cab and its trailer.
3D Semantic Segmentation: The Gold Standard of Precision
Semantic segmentation takes a different approach. Instead of drawing a box around a cluster of points, every single individual point in the cloud is assigned a specific class (e.g., "road," "vegetation," "vehicle," "curb").
Key Characteristics:
- Point-Wise Classification: There is no "empty space" in the label. If a point is labeled "car," that point is physically part of the car's surface.
- Boundary Precision: It defines the exact contours of an object.
- Use Cases: Essential for robotic grasping (knowing exactly where to place a mechanical hand) or sidewalk navigation (differentiating a flat road from a 2-inch curb).
Common Types of 3D Annotation
Depending on what you are building, you generally need one of two things:
- 3D Cuboid Annotation: Drawing a 3D box around objects (like cars or trees). This tells the AI the object’s height, width, length, and orientation.
- 3D Semantic Segmentation: The most granular form of labeling. Every single point in the cloud is assigned a class (e.g., "road," "sidewalk," "building"). This is essential for fine-tuned navigation.
Comparison at a Glance
|
Feature |
3D Bounding Boxes (Cuboids) |
3D Semantic Segmentation |
|
Granularity |
Object-level |
Point-level |
|
Output |
Box coordinates + Heading |
Per-point Class ID |
|
Annotation Speed |
Fast |
Very Slow / Intensive |
|
Primary Goal |
Detection & Tracking |
Environmental Understanding |
|
Accuracy Required |
High (Centimeters) |
Extreme (Millimeters) |
The "Why Manual?" Angle: Where Every Centimeter Matters
It is no secret that 3D semantic segmentation is tedious. Manually classifying millions of points is the most labor-intensive task in the data annotation world. Because of this, many companies try to automate it using pre-trained models.
The problem? Automation fails at the boundaries.
When a robot is trying to navigate a narrow doorway or a delivery drone is landing on a porch, the difference between a "clear path" and an "obstacle" is often just a few centimeters of points.
- Boundary Bleeding: Automated tools often "bleed" labels, incorrectly marking points of a wall as part of the floor.
- The "Grasping" Failure: In logistics, if a robot’s "grasping" model is trained on automated labels that are off by 5mm, the robot will consistently drop items or collide with its environment.
Why HITL is Vital
Manual Human-in-the-Loop (HITL) segmentation ensures that these critical boundaries are respected. Our annotators don't just "paint" a scene; they use spatial reasoning to determine exactly where a sidewalk ends and a driveway begins—nuance that current automated tools consistently miss.
Conclusion: Which Does Your Model Need?
If your goal is simple obstacle avoidance at high speeds (like highway driving), 3D Bounding Boxes are likely your most cost-effective path.
However, if your project involves high-precision interaction with the environment—think warehouse robotics, urban sidewalk delivery, or surgical assistance—3D Semantic Segmentation is not just an option; it is a requirement.



{kind=link}
{kind=link}
{kind=link}