

Why Auto-Labelling Still Needs A Human Reality Check
29/04/2026
The Beginner’s Guide to 3D Point Cloud Annotation: Navigating the Z-Axis
7 min read
In this article, you'll learn about what a 3D point cloud is, how it underpins 3D AI models and why Human-in-the-loop (HITL) methods prevail.
As we move toward a world of autonomous vehicles, spatial computing, and warehouse robotics, machines need to understand the world the same way we do: in three dimensions. But 3D data is messy. It’s sparse, it’s massive, and it’s notoriously difficult to label. In this guide, we’ll break down what 3D point cloud annotation is and why the "human touch" remains the most critical component of the pipeline.
What Exactly is a 3D Point Cloud?
At its simplest, a point cloud is a collection of individual data points in a three-dimensional coordinate system. These points are typically generated by LiDAR (Light Detection and Ranging) or RGB-D cameras.
Unlike a standard photo, which is a grid of pixels, a point cloud represents the external surface of an object or an environment. Every single point in that "cloud" contains specific spatial information:
- Coordinates: Each point is defined by (X, Y, Z) values representing its position in space.
- Intensity: A measure of how much light reflected back to the sensor (often used to distinguish materials).
- RGB (Optional): Sometimes color data is overlaid onto the spatial data.
When you have millions of these points clustered together, they form a "ghostly" but highly accurate 3D map of the world.
Why 3D Annotation is a Different Beast
If 2D annotation is like drawing in a coloring book, 3D annotation is like digital sculpting. Here is why it’s significantly more complex:
- Depth Perception: In a 2D image, an object is either "up, down, left, or right." In a 3D cloud, an annotator must account for depth and distance.
- Occlusion & Sparsity: Objects that are far away from the sensor might only consist of 5 or 10 points. To a machine, that looks like noise. To a trained human annotator, those 10 points represent a pedestrian.
- Rotation (Yaw, Pitch, Roll): A 3D bounding box (a "cuboid") doesn't just sit on a screen; it must be perfectly aligned with the object's orientation in 3D space.
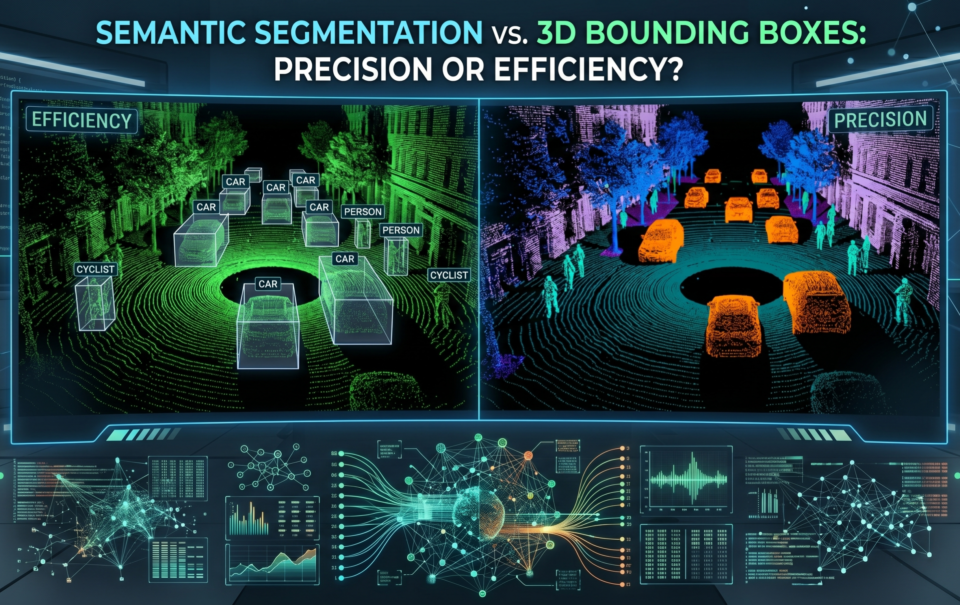
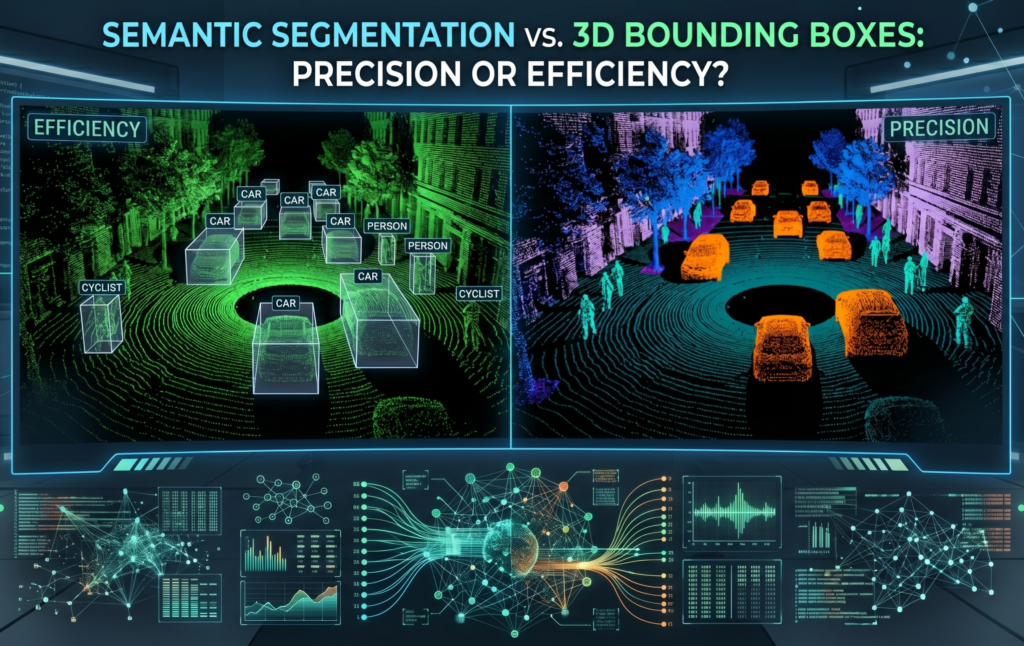
Common Types of 3D Annotation
Depending on what you are building, you generally need one of two things:
- 3D Cuboid Annotation: Drawing a 3D box around objects (like cars or trees). This tells the AI the object’s height, width, length, and orientation.
- 3D Semantic Segmentation: The most granular form of labeling. Every single point in the cloud is assigned a class (e.g., "road," "sidewalk," "building"). This is essential for fine-tuned navigation.
The HITL Advantage: Why Manual is the Gold Standard
We often get asked: "Can’t an AI just label this for me?"
There are plenty of "auto-labeling" tools on the market, and they are great for simple, high-density data. But AI models are only as good as their Ground Truth. If you use a machine to label your training data, you are essentially asking your model to "guess based on a guess."
Human-in-the-Loop (HITL) manual annotation provides the precision that machines can't yet replicate:
- Contextual Reasoning: A human can distinguish between a "mailbox" and a "small child" based on the environment, even if the point density is low.
- Edge Case Mastery: When a sensor glitches or weather creates "ghost points," a manual annotator can filter out the noise that would otherwise confuse an autonomous system.
- Unmatched Accuracy: For safety-critical applications (like medical robotics or self-driving cars), 95% accuracy isn't enough. Manual intervention is the only way to approach that 99.9% threshold.
Final Thoughts
3D point clouds are the future of how machines perceive reality. However, the bridge between "raw data" and "intelligence" is built through meticulous, high-quality annotation.
In our next post, we’ll dive deeper into the "Auto-Labeling Myth" and explore why the world's leading ML teams are still doubling down on manual, human-led data verification.


{kind=link}
{kind=link}
{kind=link}