

The Beginner’s Guide to 3D Point Cloud Annotation
21/04/2026
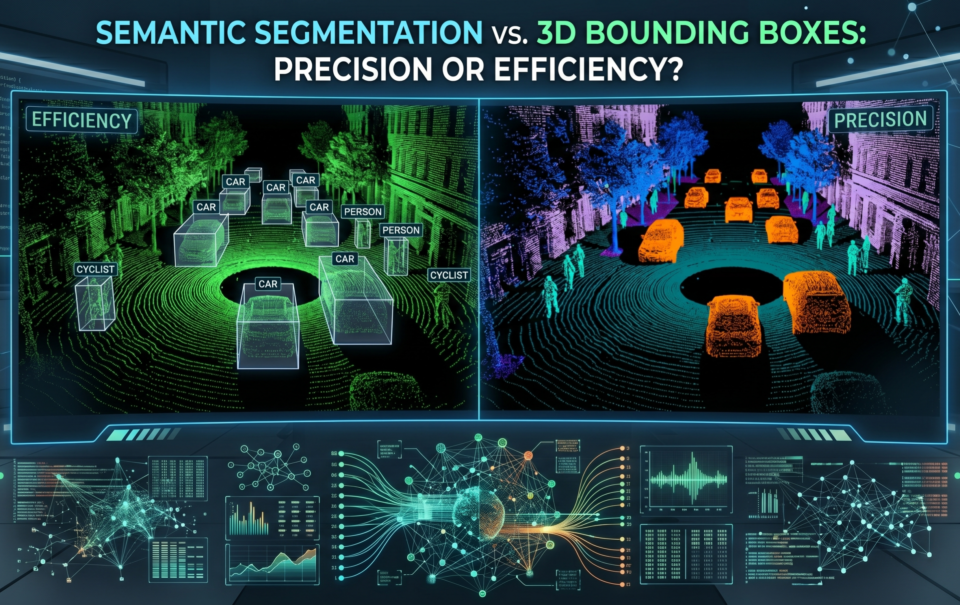
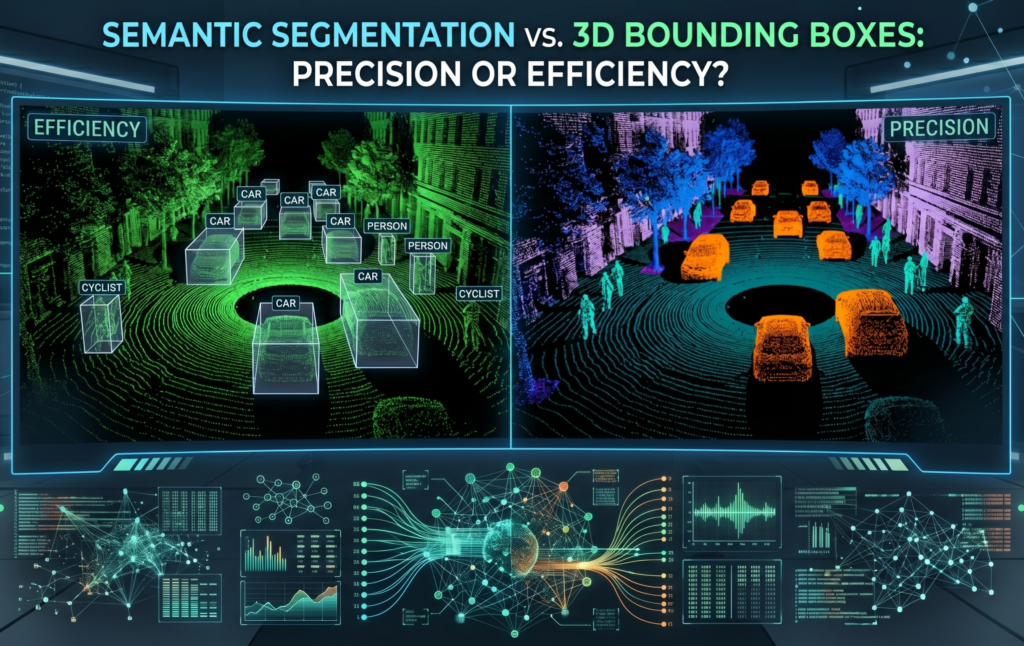
Semantic Segmentation vs. 3D Bounding Boxes: Precision or Efficiency?
29/04/2026
Why Auto-Labeling Still Needs a Human Reality Check
4 min read
In this article, you'll learn about the challenges faced by 3D space and how human intelligence can lay the foundations for successful AI models.
But here is the hard truth: AI cannot be its own teacher.
When you use an auto-labeller to generate training data, you aren't creating ground truth; you’re creating a "best guess" based on existing patterns. In the high-stakes world of 3D point clouds, a "guess" isn't good enough. Here is why the Human-in-the-Loop (HITL) model is more than a safety net; it’s a mathematical necessity.
The Pattern Trap: Why Machines Miss the "Weird"
Auto-labelers are essentially ML models themselves. They work by recognizing statistical patterns. If a machine sees a cluster of points that looks 90% like a car, it labels it a car.
But the real world is messy, chaotic, and rarely follows a 90% pattern. Machines struggle with Edge Cases: the anomalies that don't fit the training set.
- The Costume Problem: A person in a T-Rex costume walking down a sidewalk doesn't "look" like a human to a machine. To a human annotator, the context (walking on a sidewalk, human-like gait) makes it obvious.
- The Debris Problem: A fallen tree or a scattered pile of cardboard boxes can be misinterpreted as a fixed barrier or a small vehicle by an auto-labeler.
- The Non-Standard Vehicle: Custom trailers, flatbed trucks carrying oddly shaped heavy machinery, or even a bicycle with a sidecar can cause an auto-labeler to "glitch" or ignore the object entirely.
The Human Edge: Humans don’t just rely on point-density patterns; we rely on context. We understand physics, human behavior, and the probability of an object's presence in a specific environment.
The 90% Ceiling: A Mathematical Death Spiral
In the world of model training, there is a concept called the Ground Truth. This is the "gold standard" data that your model uses to learn what is right and what is wrong.
"If your ground truth is only 90% accurate because of auto-labeling errors, your model’s performance ceiling is 90%."
If you train a model on "noisy" or slightly incorrect data, the model will eventually treat that noise as the truth. Over time, this leads to Model Drift. You might save money upfront on cheap, automated labeling, but you pay for it later in:
- Engineering Hours: Spent trying to figure out why the model is failing in the field.
- Safety Risks: A 10% failure rate in an autonomous system is catastrophic.
- Re-work Costs: Eventually, you’ll have to hire humans to fix the automated mistakes anyway.
Accuracy Comparison: Auto vs. Manual HITL
|
Feature |
Auto-Labeling (Standalone) |
Manual HITL Service |
|
Accuracy |
~85% – 92% |
Up to 99.5% |
|
Edge Case Handling |
Poor (often ignored or mislabeled) |
Exceptional |
|
Consistency |
High (but consistently wrong) |
Verified through QA |
|
Setup Time |
Fast |
Measured & Scalable |
|
Reliability for Safety |
Not Recommended |
Industry Standard |
Pushing the Needle to 99.5%
At GreatRock<bits>, we don’t view automation as a replacement; we view it as a tool that must be audited.
Our full manual service ensures that every cuboid is snug, every semantic point is correctly classified, and every "weird" object is accounted for. By using a human-centric workflow, we push your data quality from "good enough for a demo" to "ready for the real world."
Don't build your AI on a foundation of guesses.


{kind=link}
{kind=link}
{kind=link}